SQL Abfragen und der Project Server 2016
Mit dem Project Server 2016 hat sich erneut die Datenbankstruktur geändert. Das SQL Schema „dbo“ heißt nun „pjrep“. Zudem beinhaltet jede Tabelle im Primary Key die Spalte „Siteld“.
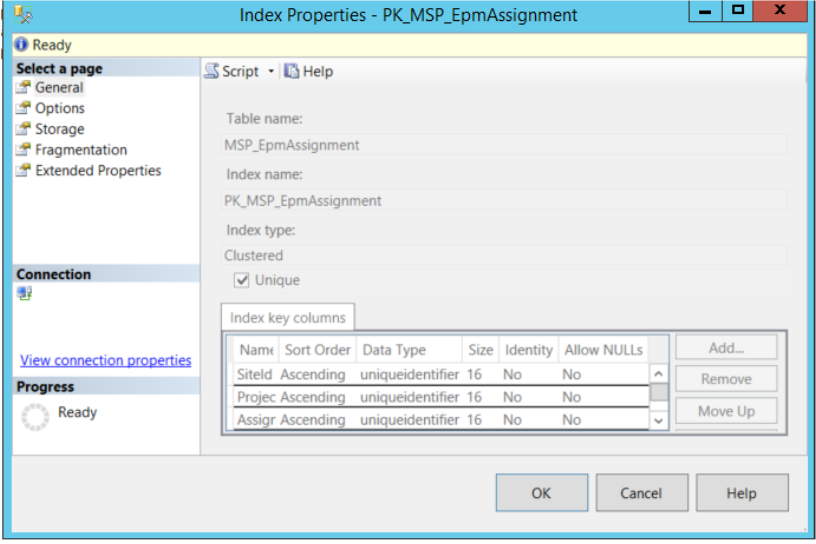
Abbildung 1) Index Eigenschaften
Wenn Sie Berichte von einer älteren Project Server Version auf die neue Version migrieren, müssen Sie das verwendete Schema ändern.
Eine weitere Problematik veranschaulicht die nachfolgende einfache Abfrage.
Hinweis: Die Option „Include Actual Execution Plan“ wurde aktiviert und folgender Text vor die Abfrage gestellt:
SET STATISTICS IO ON;
GO
Die daraus resultierenden Meldungen können Sie mittels http://statisticsparser.com/ in eine Tabellenform umwandeln.
SET STATISTICS IO ON;
GO
SELECT
p.ProjectUID, t.TaskUID, a.TaskUID, r.ResourceUID, p.ProjectName, t.TaskName, a.AssignmentActualWork, r.ResourceName
FROM pjrep.MSP_EpmProject as p
INNER JOIN pjrep.MSP_EpmTask as t
ON p.ProjectUID = t.ProjectUID
INNER JOIN pjrep.MSP_EpmAssignment as a
ON t.TaskUID = a.TaskUID
INNER JOIN pjrep.MSP_EpmResource as r
ON a.ResourceUID = r.ResourceUID
WHERE p.ProjectType = 0
;
Unter Messages werden Informationen angezeigt, die in etwa wie folgt aussehen:
Table ‚Workfile‘. Scan count 0, logical reads 0, physical reads 0, read-ahead reads
Table ‚Worktable‘. Scan count 0, logical reads 0, physical reads 0, read-ahead reads
Table ‚MSP_EpmAssignment‘. Scan count 1, logical reads 478, physical reads 0, read-
Table ‚MSP_EpmTask‘. Scan count 1, logical reads 2197, physical reads 0, read-ahead
Table ‚MSP_EpmProject‘. Scan count 1, logical reads 52, physical reads 0, read-ahead
Table ‚MSP_EpmResource‘. Scan count 1, logical reads 15, physical reads 0, …
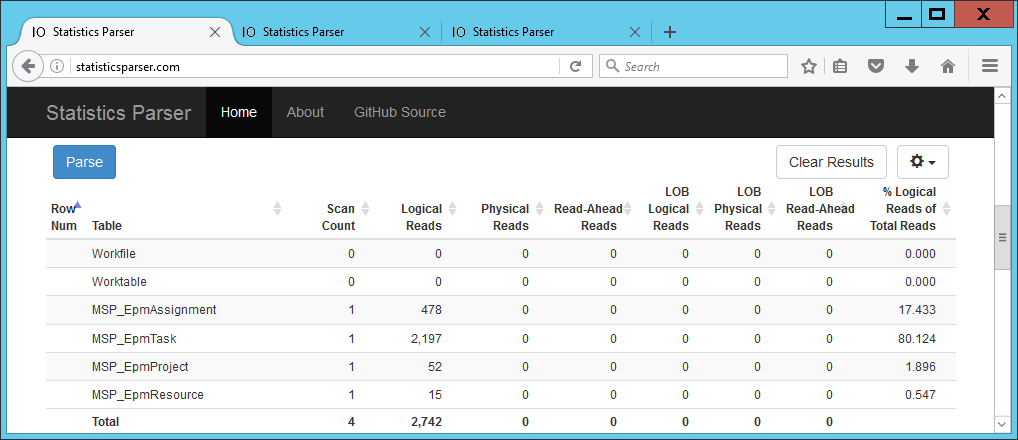
Wird dieser Text in http://statisticsparser.com/ eingegeben, erhält man folgenden Ausführungsplan:
Abbildung 2) IO-Statistiken von Query1
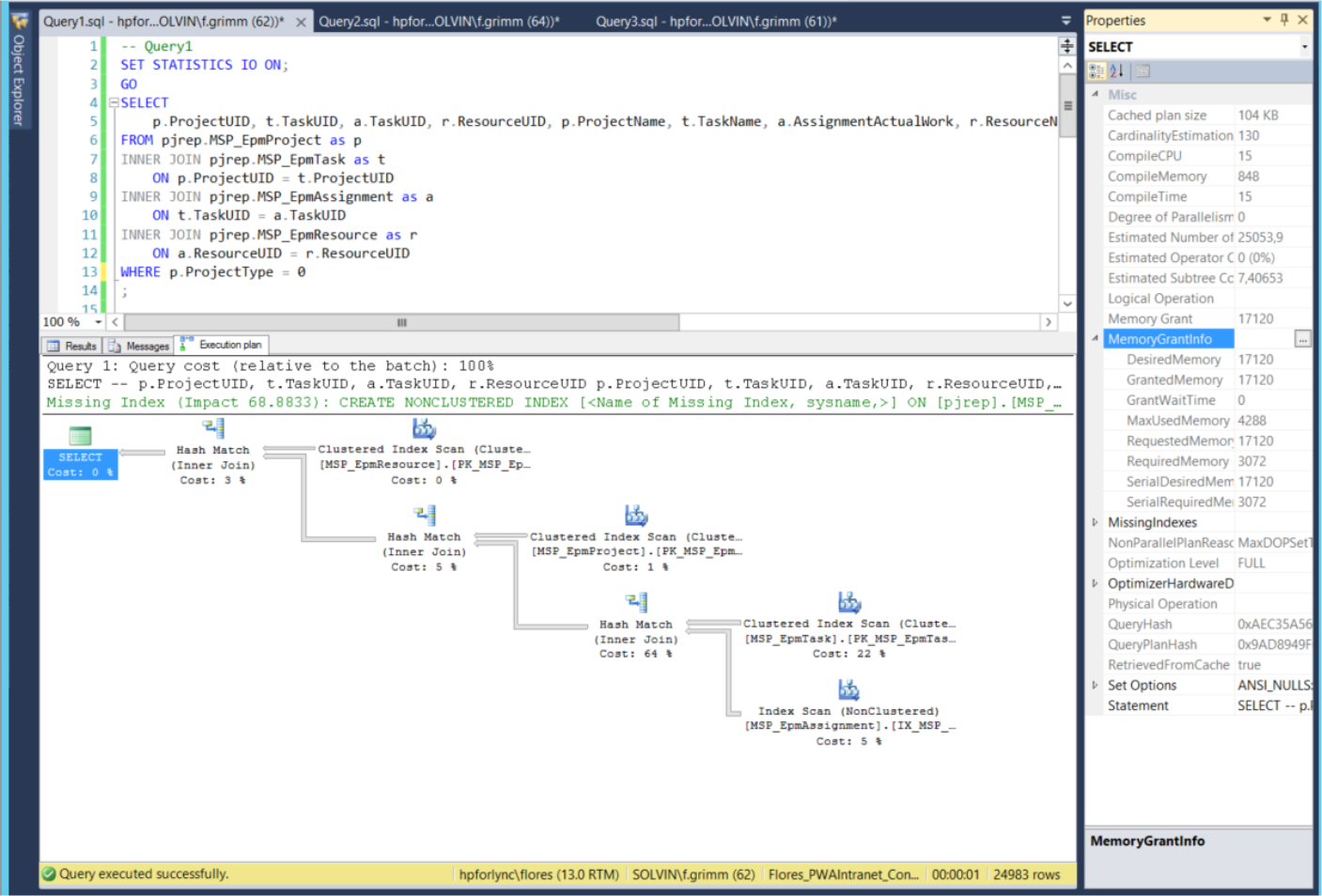
Der Ausführungsplan zeigt mehrere „Clustered Index Scan“.
Abbildung 3) Der Ausführungsplan von Query1
„Clustered Index Scan“ = Lese die komplette Tabelle
„Index Scan“ = Lese den kompletten Index
Die Verarbeitungszeit ist mit 1 Sekunde akzeptabel. Etwas versteckt findet sich die Information MemoryGrantInfo/GrantMemory. In diesem Fall liefert sie die Zahl 171270. Was bedeutet, dass der Speicherverbrauch bei 171270 Kilobyte liegt.
Es sind 3 „Hash Match“ zu sehen. Ein „Hash Match“ funktioniert so, dass zuerst die eine Tabelle komplett gelesen wird und anschließend die andere Tabelle. Dabei wird der Join berechnet. „Hash Match“ ist ein „Stop Operator“. Das heißt, er liefert erst Daten, wenn die Eingaben komplett geladen und verarbeitet sind. Das erklärt den Speicherverbrauch. Auf einem SQL Server, der nur von den Berichtsentwicklern benutzt wird, ist das kein Problem. Auf der produktiven Umgebung, mit vielen Abfragen / Operationen gleichzeitig, ist das problematisch. Um dieses Problem zu lösen, nutzen Sie die Indexe. Diese Abfrage, ausgeführt auf der Project Server Datenbank, liefert Ihnen eine Übersicht aller Indexe und Spalten:
SELECT SCHEMA_NAME(o.schema_id),o.name,i.name, i.type_desc,
COL_NAME(ic.object_id,ic.column_id) AS column_name,
ic.index_column_id,ic.key_ordinal,ic.is_included_column
FROM sys.all_objects o
INNER JOIN sys.indexes i
ON i.object_id = o.object_id
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
where SCHEMA_NAME(o.schema_id) = ‚pjrep‘ AND o.name LIKE ‚MSP_Epm%‘
ORDER BY SCHEMA_NAME(o.schema_id), o.name, i.type, i.name, ic.index_column_id
Abbildung 4) Ausschnitt aus dem Ergebnis der Index Abfrage
Wenn Sie dieselbe Abfrage umschreiben, so dass die vorhandenen Indexe verwendet werden, erhalten Sie folgenden Ausführungsplan:
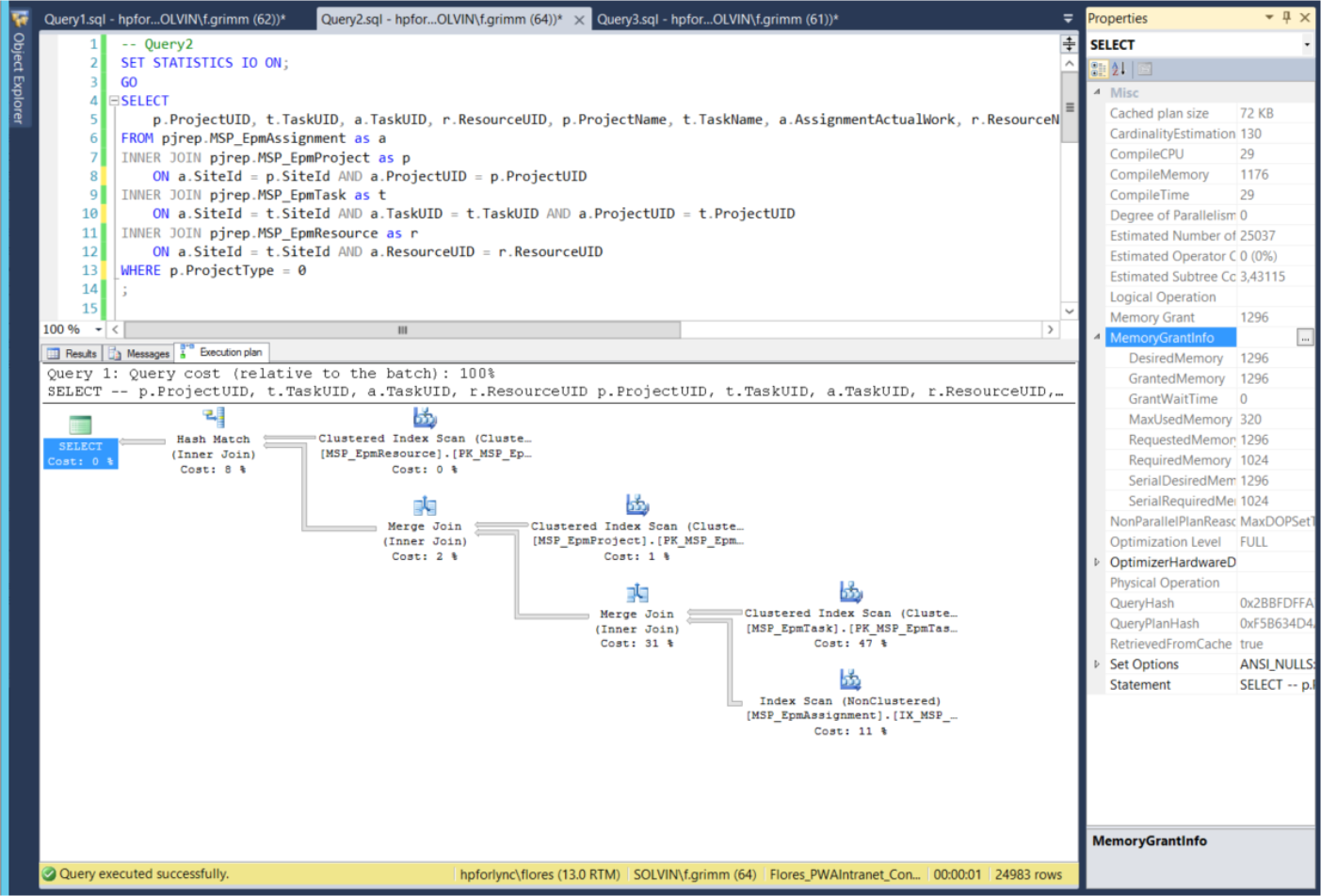
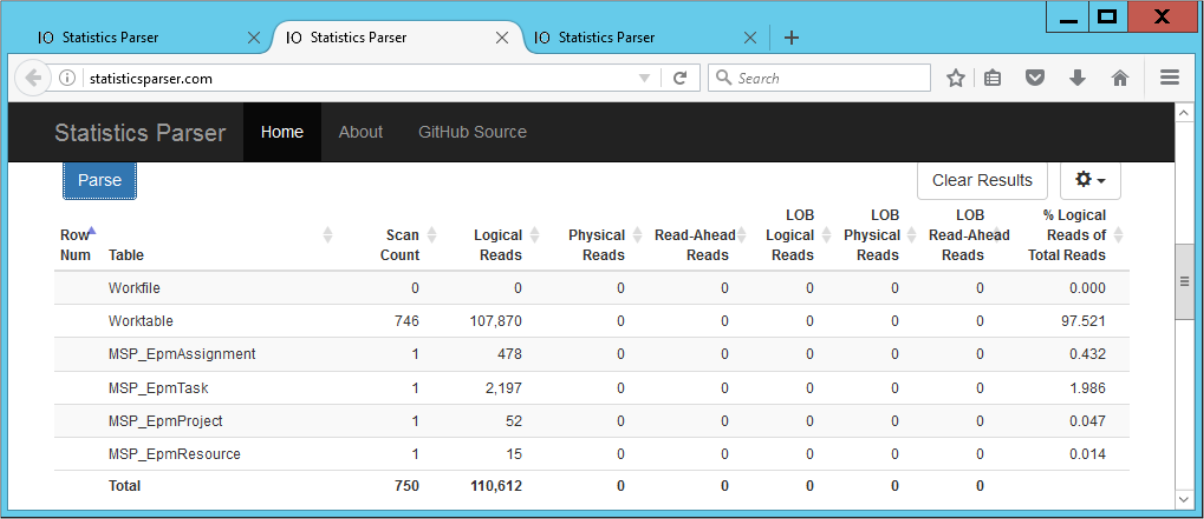
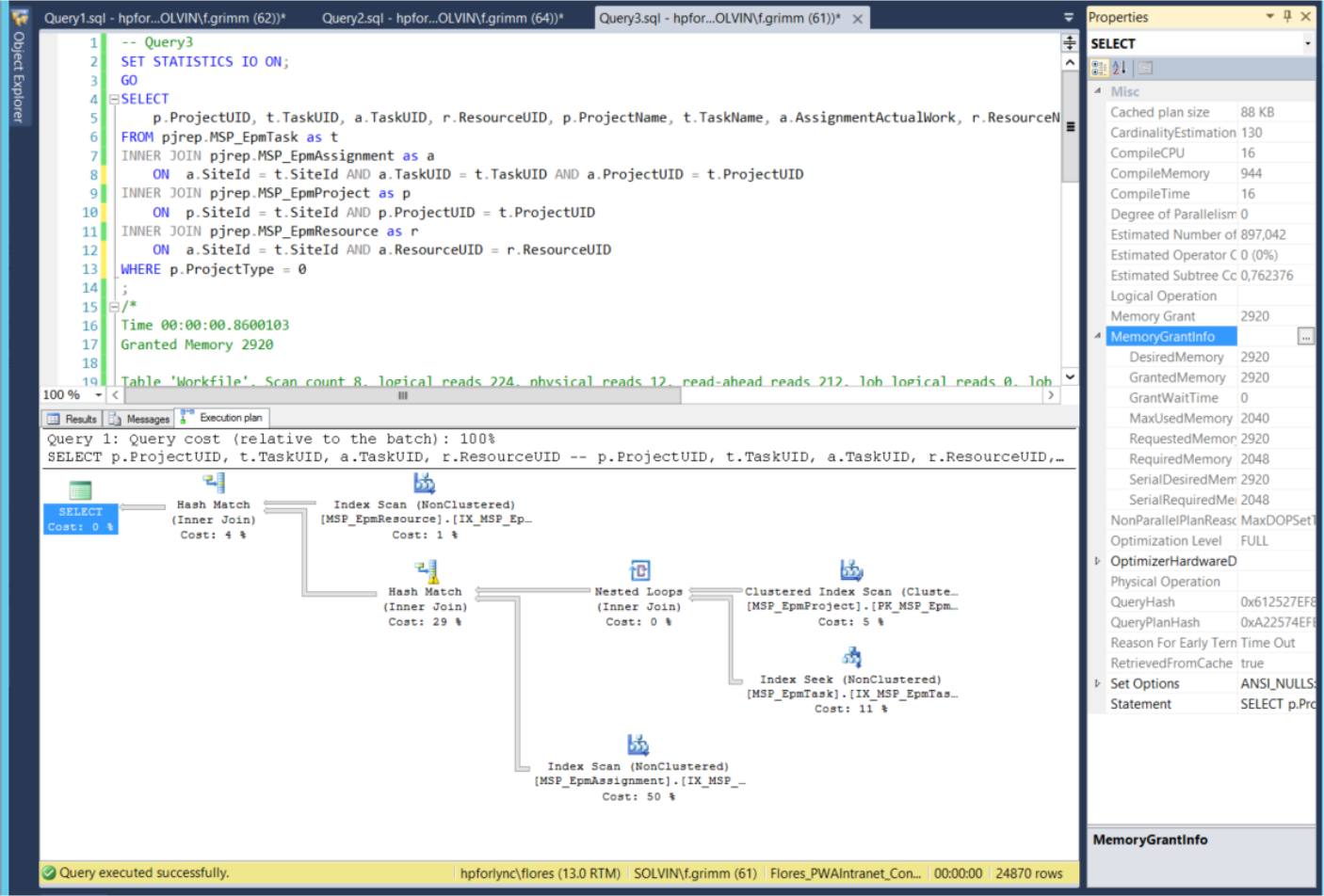
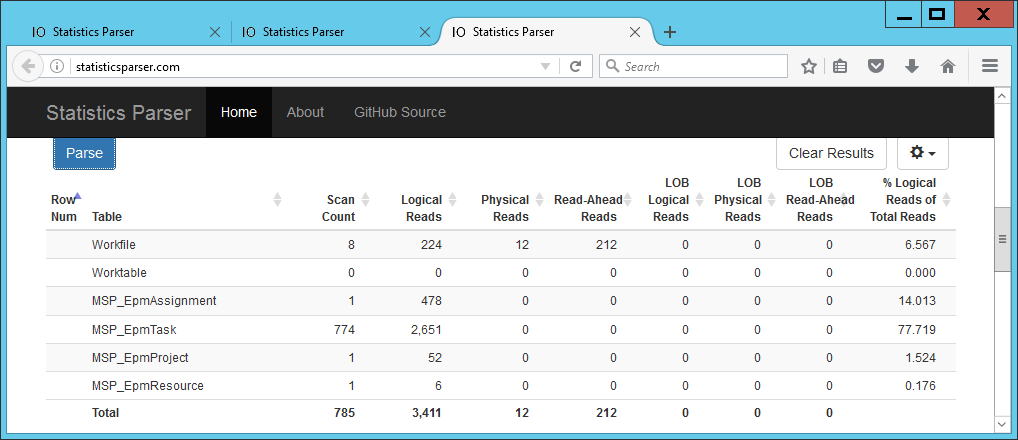
Abbildung 5) Der Ausführungsplan von Query2
Der Speicherverbrauch liegt jetzt nur noch bei 1296 Kilobyte. Es wird zweimal ein „Merge Join“ verwendet. Ein „Merge Join“ liest zwei Tabellen gleichzeitig und berechnet das Ergebnis sofort. Die Daten werden sofort an den nächsten Operator weitergegeben.
Die IO-Statistiken zeigen:
Abbildung 6) IO-Statistiken von Query2
Der Eintrag „Worktable“ resultiert aus internen Hilfsoperationen. Eine dritte Variante, die andere Indexe verwendet, verhält sich entsprechend anders:
Abbildung 7) Der Ausführungsplan von Query3
Der Speicherverbrauch liegt bei 2920 Kilobyte und die IO-Statistiken zeigen:
Abbildung 8) IO-Statistiken von Query3
Wie sieht nun also der richtige Weg aus? Wenig ist gut. Denn wenig IO bedeutet weniger Speicher und daher weniger Zeit.
Ein (1) „Clustered Index Scan“ oder „Index Scan“ wird in vielen Abfragen zu finden sein. Dieser ist für große Datenmengen auch die schnellste Variante. Ein „Join“-Operator kann gut arbeiten, wenn er einen Index findet, welcher die angegebenen Spalten enthält.
Wenn man mehrere Scans findet, wird vermutlich auch der Speicherverbrauch in die Höhe schießen. Das Problem der ersten Abfrage ist, dass die Spalte „SiteId“ nicht verwendet wird und deshalb auch kein Index gefunden wird, welche die Abfrage verwenden kann, um performant zu sein.
Das Skript, das die Indexe anzeigt, liefert schnell die benötigten Informationen. Die Alternative wäre: Tabelle suchen, Indexe durchsuchen indem man den Index-Eigenschaften-Dialog öffnet. Das ist doch eher mühsam.
Fazit: Achten Sie bei der neuen Project Server Datenbank darauf, dass Sie die „SiteId“ verwenden.